The Help Stop TB team is hard at work analyzing the data they’ve received so far from World Community Grid. They recently chose two new data analysis tools, which will help them better understand the behavior of the bacterium which causes tuberculosis.
Hello everyone, and thank you for contributing your computer time to Help Stop TB! We would have never completed so many simulations if it wasn’t for you!
Background
Help Stop TB was created to examine a particular aspect of the highly resistant and adaptable bacterium that causes tuberculosis. The bacterium has an unusual coat which protects it from many drugs and the patient's immune system. Among the fats, sugars and proteins in this coat, the TB bacterium contains a type of fatty molecules called mycolic acids. Our project simulates the behavior of these molecules in their many configurations to better understand how they offer protection to the TB bacteria. With the resulting information, scientists may be able to design better ways to attack this protective layer and therefore develop better treatments for this deadly disease.
Choosing Data Analysis Tools and Methods
Since our previous mini update in November, Athina has been focusing on analysing our simulation data, and at the same time she is writing up her PhD thesis. As a team, we have now achieved our main goal, which was to come up with a robust and efficient analytical strategy. This will enable us to efficiently process the heaps of data we’re receiving from the simulations conducted by World Community Grid volunteers, and will answer our questions about mycolic acids’ conformational behaviour and its biological implications.
The analysis protocol that we have decided on combines a variety of different analytical tools and methods. One of the tools we are using is a PCA (principal components analysis) clustering technique developed at the School of Pharmacy at the University of Nottingham. This tool has helped us categorise the shapes that mycolic acids adopt throughout the simulations. In turn, this gives us a clearer idea about which shapes are the most dominant ones.
Figures 1 and 2 below are examples of how we are looking at the shapes of mycolic acids. These structures are important as we are looking at all the possible conformations that mycolic acids can assume in order to try to understand how those molecules work, how their conformations dictate any biological implications and/or affect the disease itself, in the hope to find any links and discover more for prevention methods.
Because it has been shown that mycolic acids tend to demonstrate complex conformational behaviours with frequent folding and unfolding events, it is important to assess the frequency of those events. Understanding the frequency in which mycolic acids change from one folding conformation into another may help underpin important aspects of their biological behaviour.
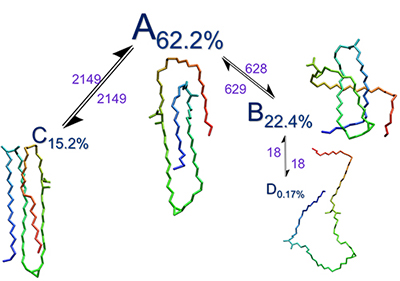
Additionally, the length of time that the molecules choose to remain in a certain adopted conformational pattern may also elucidate further biological implications. Each molecule assumes different shapes throughout its folding pathway and these shapes can be very dependent to each other. From the PCA clustering tool data, we have extracted important information regarding the dependency (Figure 1) between the different shapes the molecules assume.
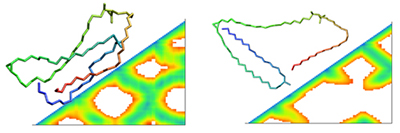
Another analytical approach that we employed was the distance matrix analysis. We created and analysed matrices (Figure 2) of the distances of all the carbon atoms along the mycolic acid chain. This method can provide further insight into the frequency of the folding events and can also help us understand more about the flexibility of each structure.
We have also tested the suitability of a dihedral angle clustering tool which was developed at the Centre for Molecular Design (CMD) at the University of Portsmouth. This tool was computationally less intensive than the distance matrix analysis, but unfortunately it could not address the frequent refolding events that the mycolic acids demonstrate, thus making it challenging to extract meaningful data. However, the test cases that we analysed with this technique confirmed the predominant clusters that we had found with our PCA tools. We will now use the best choice of analysis options to build a picture for all the different mycolic acids, and will subsequently link the individual behaviour with experimental data on mycolic acid population in bacterial cell walls and their individual roles therein.
That was all our news for now! Thank you again for your contributions, and let’s all wish good luck to Athina with her writing! Until the next time, happy crunching!
Related Articles
- Researchers Partner with World Community Grid to Help Stop a Leading Killer
- Help Stop TB Researchers Begin First Stages of Data Analysis
- Help Stop TB Uncovers New Data on Mycolic Acids
- Help Stop TB Researchers Seek New Team Members
- A Graduation, a Paper, and a Continuing Search for the Help Stop TB Researchers